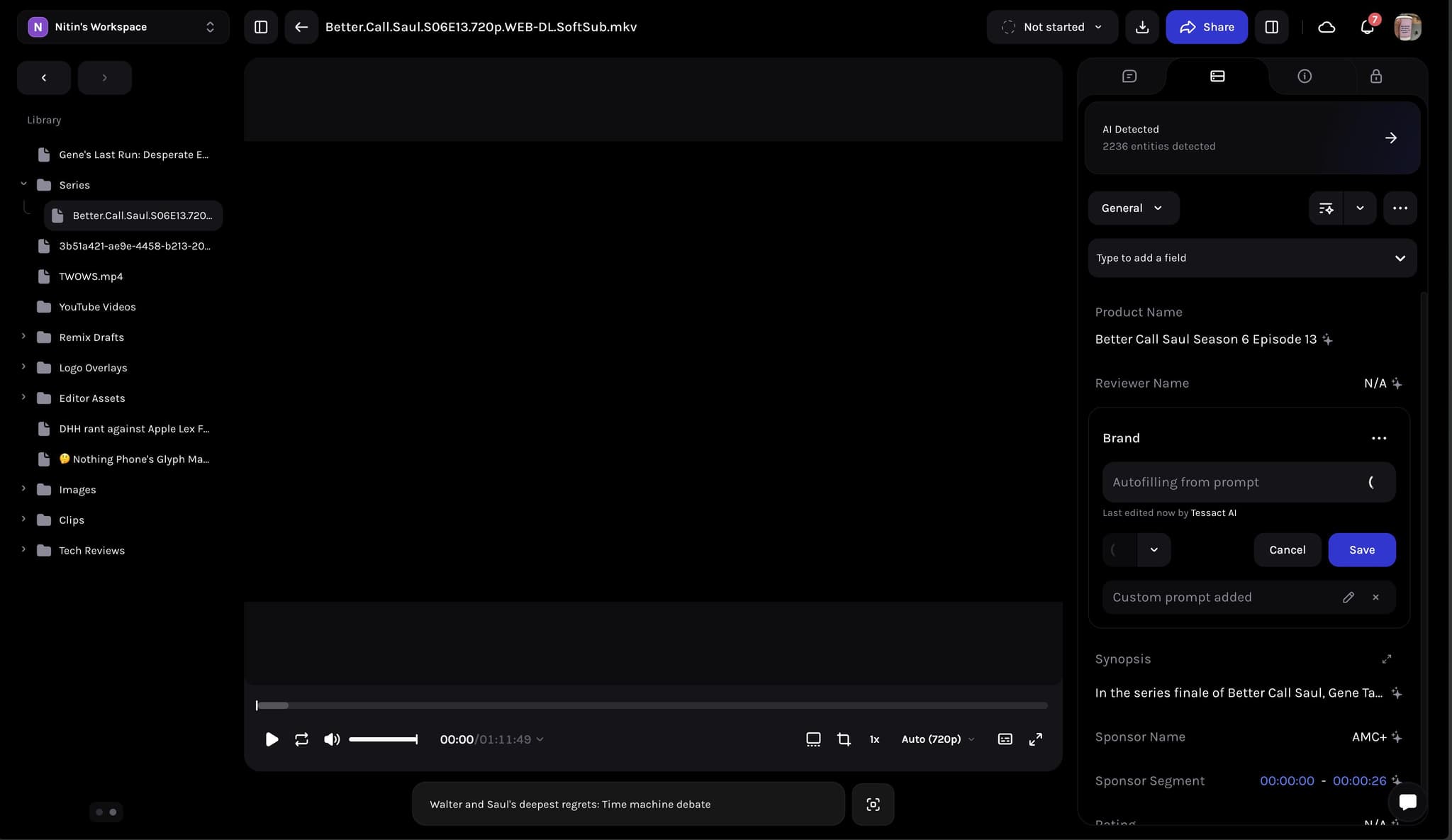
AI-Powered Metadata Autofill
I developed a system that uses AI to automatically fill in metadata for media assets. Editors can select a file and specify which metadata fields or categories they want to populate. The system then analyzes the file's content—such as video scenes or audio transcripts—and uses a large language model to generate accurate and relevant metadata. The results are then saved directly to the asset, saving editors significant time on manual data entry.
Tech Stack
FastAPI, ElasticSearch, LangGraph, Pydantic-AI, Google Gemini
My Role
I designed and implemented the end-to-end pipeline for this feature. This involved creating a FastAPI endpoint, orchestrating the data fetching and AI processing using a graph-based architecture, and integrating with internal services for data retrieval and storage. The core of the system uses an AI agent to intelligently generate metadata based on the context of the media file.
1. Developed a robust data pipeline to gather context for the AI, including fetching video scene data from Elasticsearch and audio transcripts.
2. Built a flexible system that can autofill metadata for entire categories or for specific, individual fields.
3. Engineered the system to process categories in parallel for improved performance.
4. Implemented the core AI logic using a Pydantic-AI agent to generate structured metadata from unstructured content.
5. Designed the system with SOLID principles in mind, ensuring it is maintainable and extensible for new metadata types.
6. Integrated with internal APIs to fetch asset details and persist the generated metadata.
Impact
1. Drastically reduced the time and effort required for manual metadata entry, allowing editors to focus on more creative tasks.
2. Improved metadata quality and consistency across all assets by leveraging AI.
3. Enhanced the searchability and organization of the media library through richer, more accurate metadata.